2つの英単語 w, w' 間の類似度σ(w, w') は,意味的な関連度に応じて 0〜1 の値(関連が強ければ大きな値)をとります.この類似度σは,英語辞書から自動生成した意味ネットワーク上の活性伝搬によって計算されます.
| σ ( waiter, | restaurant ) | = 0.175699 |
| σ ( computer, | restaurant ) | = 0.003268 |
| σ ( red, | orange ) | = 0.264262 |
| σ ( red, | blood ) | = 0.111443 |
| σ ( green, | blood ) | = 0.002268 |
| σ ( dig, | spade ) | = 0.116200 |
| σ ( fly, | spade ) | = 0.003431 |
具体的には,英語辞書(LDOCE)の見出し語をノードとし,語義定義に現われる単語をリンクに変換します.この意味ネットワーク上で,ノードw から〈エネルギー〉を伝搬させ,ノードw' が受け取った〈エネルギー〉を観察し,その値を類似度σとしています.(下図は,この活性伝搬の様子を,縦軸を〈エネルギー〉・横軸を時間として表わしたものです.)
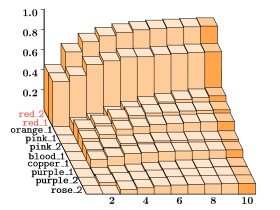
この類似度σは,テキスト言語学でいう lexical cohesion にあたるものです.これによってテキストの意味を数量化し,コンピュータによる意味処理,に信号処理や統計処理の手法を応用できるようにしました.
おもな論文・著書──
- Kozima Hideki, Teiji Furugori: Similarity between words computed by spreading activation on an English dictionary, Conference of the European Chapter of the Association for Computational Linguistics (EACL-1993; Utrecht, the Netherlands), pp.232-239, 1993.
〈テキスト=セグメンテーション〉とは,ベタ書きのテキスト(ニュース記事や物語などの文章)を意味段落に区切っていくことです.区切りを見つける方法はいろいろ考えられますが,上記の〈単語間の意味的な類似度〉を利用した方法を考案しました.
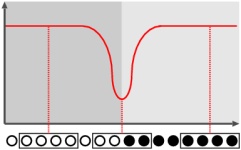
原理は簡単です.テキスト(単語列)の上を移動する〈窓〉を用意します.この〈窓〉からは(一定語数の)部分列が見えます.この部分列に含まれる各単語間の平均類似度Σを計算し,その窓の位置にプロットすることで,グラフ(赤線)──LCP (Lexical Cohesion Profile) と呼びます──が得られます.〈窓〉が意味段落の内部にあればグラフは高い値を保ちます.〈窓〉が意味段落の境界上にあれば,その〈窓〉から見える部分列は意味的な一貫性を失うため,グラフは極小値をもつようになります.つまり,グラフの極小点から,テキストの意味的な区切りを見つけられるわけです.
おもな論文・著書──
- Kozima Hideki: Text segmentation based on similarity between words, Annual Meeting of the Association for Computational Linguistics (ACL-1993; Ohio, USA), pp.286-288, 1993.
- Kozima Hideki, Teiji Furugori: Segmenting narrative text into coherent scenes, Literary and Linguistic Computing, Vol.9, pp.13-19, 1994.
単語間の類似度は文脈によって変化します.たとえば,bus から何を連想するかを考えた場合,エンジニアは engine や wheel を連想し,旅行者は tourist や timetable を連想するでしょう.そこで,文脈を単語集合 C として与え,その文脈の意味的な分布を考慮して,C から意味的に関連した単語を連想する手法を考えました.
たとえば以下の例にあるように,文脈 C = {bus, car, railway} としたとき,この手法によって C から連想された単語群(連想度順にソート)には,motor や wheel や engine などの単語がみられます.
- {bus, car, railway} →
- car, bus, motor, carriage, motor, passenger, vehicle, garage, road, inside, wheel, engine, ...
- {bus, scenery, tour} →
- bus, scenery, tour, abroad, tourist, passenger, make, everywhere, garage, set, machinery, something, timetable, ...
- {read, magazine, paper} →
- paper, read, magazine, newspaper, print, book, print, wall, something, article, specialist, that, ...
- {read, machine, memory} →
- machine, memory, read, computer, remember, someone, have, that, instrument, feeing, that, what, ...
おもな論文・著書──
- Kozima Hideki, Akira Ito: Context-sensitive word distance by adaptive scaling of a semantic space, R. Mitkov, N. Nicolov (eds.), Recent Advances in Natural Language Processing, Contemporary Issues in Linguistic Theory 136, Amsterdam: John Benjamins, pp.111-124, 1997.
- 小嶋 秀樹・伊藤 昭: 文脈依存的に単語間の意味距離を計算する一手法, 情報処理学会論文誌, Vol.38, No.3, pp.481-489, 1997.